搜索到
4
篇与
的结果
-
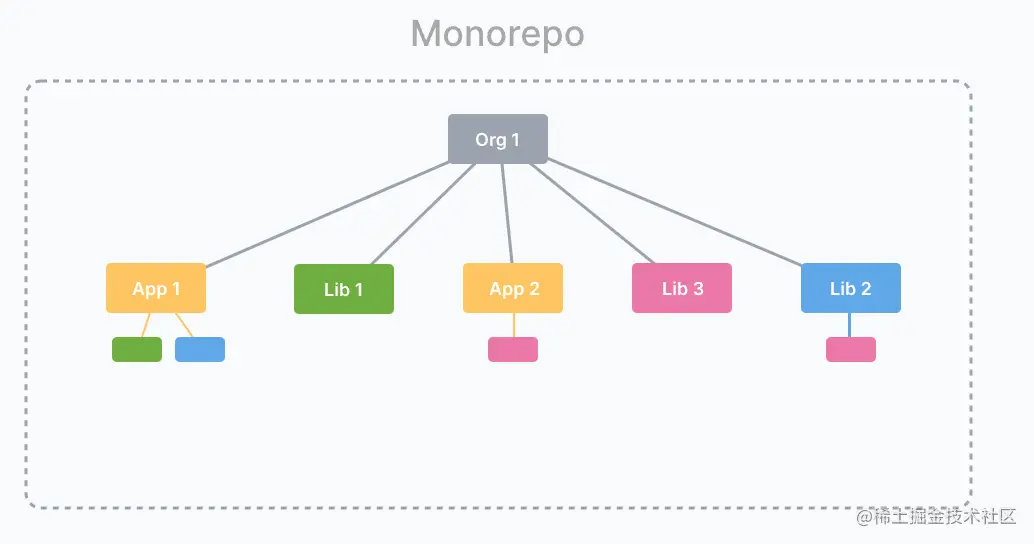
 Monorepo模式 什么是 Monorepo?一个 Monorepo 是一个单一的存储库,包含 多个不同的项目 ,和 明确的关系 。和 Monorepo 对立的是传统的 Polyrepo 模式,每个项目对应一个单独的仓库来分散管理现代的前端工程越来越多的都会选择 Monorepo 的方式进行开发,比如 Vue、React 等知名开源项目都采用的 Monorepo 的方式进行管理。Monorepo 的组织方式如下├── packages | ├── pkg1 | | ├── package.json | ├── pkg2 | | ├── package.json ├── package.json在 packages 目录下存放多个子项目,当然也可以叫其他名字,每个子项目都有自己的 package.json 文件,用来管理子包。在更换新的方式之前,一定要知道原先的方式有什么缺点。接下来就先聊聊 Polyrepo 的方式在生产上都存在着哪些弊端。Polyrepo 的弊端1. 代码重复Polyrepo 容易导致代码重复,主要是因为不同的项目都有自己的独立代码仓库。在维护一些基础组件或者工具函数时,会想着直接从 A 仓库将代码复制到 B 仓库里使用,这样很方便,但是却给后续维护成本带来了很大的负担。一旦出现需要修改的地方,需要在 多个仓库中进行修改 ,这可能会导致修改过程出现错误,并可能导致代码的不一致。那么当然我们可以不进行复制,将公共逻辑抽离出来,单独发包,作用一个 npm 模块引入到项目中,需要修改时,也只用修改一份代码,然后重新发布即可。但是这整个流程还是太复杂了,并不是完美的解决方式,仅仅是为了修改一点点东西,就需要去发包、更新,这太麻烦了。小结:不同仓库之间的割裂感、导致复用代码的成本很高,开发体验差。或者需要在多个仓库中重复编写相同的代码,从而导致代码的不一致性和冗余性。2. 版本管理因为多个仓库分别管理自己的代码,这样会缺乏一个 全局视角去看待所有仓库 ,无法清晰的了解到整个项目的结构和状态。当不同仓库中的有依赖关系时,会有依赖管理的问题,时时刻刻都需要注意依赖的版本和代码是否一致例如:主项目依赖了子项目提供的组件,如果此时子项目在某次升级时产生了 breaking change 版本,和原来的组件使用方式完全不一致,这样主项目就直接寄了。因此我们需要在子项目更新时,及时的更新主项目的依赖,这样就形成了负担。当组件出现异常时,就会开始怀疑包版本是否不正确...因此,Polyrepo 需要有合适的版本管理方法,保证版本和代码的一致性3. 工具混乱每个项目都使用自己的一组命令来运行测试、构建、服务、检查、部署等。不一致会导致记住在不同项目中使用哪些命令的心理负担。单独部署、独立工作流在多仓库情况下,由于在不同的仓库里,继承测试会变得更加的困难,需要很多步骤才能组合在一起测试。同时每个项目都使用自己的一组命令来运行测试、构建、服务、检查、部署等。不一致会导致记住在不同项目中使用哪些命令的心理负担,维护起来也是问题例如:每个项目都会配置自己的 webpack.config.js 文件,但是这些配置很多都是一致的。例如:CI、CD 流程很难将多个仓库组合到一起去,测试也比较难处理4. 代码共享要跨存储库共享代码,可能会为共享代码创建一个存储库。那么必须设置工具和 CI 环境,将提交者添加到存储库,并设置包发布以便其他存储库可以依赖它。让我们不要开始跨存储库协调第三方库的不兼容版本....5. 代码管理基于 Polyrepo 管理,每个开发人员的 commit 都会提交到各个仓库,不利于代码的 CR,也不利于管理代码合入机制,导致容易出现逃逸现象。Monorepo 能解决什么问题?Monorepo 都能解决以上的问题不仅仅在于减少了维护和管理多个代码库的成本,同时还有以下优点:代码复用 :因为多个项目共享一个代码库,所以避免了在不同项目中重复编写相同功能代码的问题,提高了开发效率。提升协作效率 :多个项目在同一个代码库中进行开发,可以方便地共享代码和文档,避免不同项目之间的沟通和协调成本。集中管理 :Monorepo 架构中,不同的应用程序都在同一个代码库中,方便管理和监控。这一点非常重要,特别是在需要同时对多个版本进行修改和维护的情况下。统一构建 :Monorepo 的一个重要特点是可以共用一套构建系统和 工具链进行构建和部署 ,提升了构建的效率。可以快速定位问题 :由于所有的代码都在同一个代码库中进行开发,debugger 可以很快找出问题所在的代码文件和行数,便于开发人员调试问题。一个版本 :无需担心因为项目依赖于第三方库的冲突版本而导致的不兼容问题。Monorepo 和 Polyrepo 的不同?前面说完之后,相信这里已经有了答案,这里再用对比的方式来看看 Monorepo 和 polyrepo 相比之下都有哪些优势依赖安装PolyrepoMonorepo每个项目都需要安装在主项目安装这里就可以看到 Monorepo 的优势在于只需一次安装,即可安装所有子项目的依赖,而 polyrepo 需要每个都单独 installCI 构建PolyrepoMonorepo各自构建增量构建:根据依赖关系(DAG),通过拓扑排序并行构建此次改动涉及到的项目Monorepo 的优势在于能够通过有向无环图,清楚的知道依赖关系,并通过拓扑排序进行增量的构建,而 Polyrepo 也有一定的优势在于无更改就不需要重新打包同时在本地开发调试、上线部署上还有着很大的优势...Monorepo 如何搭建?最简单的方式是采用 pnpm + workspace 来搭建,不需要其他额外的工具,利用 pnpm 提供 filter 命令,基本可满足大部分场景。搭建方式也很简单可以├── packages | ├── pkg1 | | ├── package.json | ├── pkg2 | | ├── package.json ├── package.json ├── pnpm-workspace.yaml在 pnpm-workspace.yaml 中指定 packages 的入口packages: # all packages in subdirs of packages/ and components/ - 'packages/**'在 pkg1 中引用 pkg2 只需要在 pkg1 的 package.json 中的依赖中进行添加"dependencies": { "@test/utils": "workspace:^1.0.0" }在根的 package.json 中通过 filter 配置 script 来指定特定的项目执行"build:pkg1": "pnpm --filter=@pkg1 build",当你的项目需要根据 package.json 下的依赖进行拓扑排序并行打包、增量打包、打包缓存、依赖图可视化等等各种功能时,你可以考虑一些构建工具比如 Rush、lerna、Turbo,这些都能高效的帮你完成想要的工作Monorepo的弊端:用Monorepo之前想一想:1.团队能否驾驭?大仓开发意味着团队每个人有全部项目的代码权限,严格的CR机制,自动化构建、测试流水线、团队整体代码水平这些都得有一定规模和经验。试想某个周五的下午一个公司新人提交了一段神秘代码,然后周末整个公司的项目全都挂了2.产出是否步调一致?无论是react还是vue他们采用Monorepo更多是因为他们产出步调一致并且存在相互关联场景,合在一起也能作为一个单独的项目发布。但是在普遍的业务项目开发中产出基本都是独立的项目,没有太多联系。例如,多个项目共用一个组件,如果有一天项目A对该组件有独特需求,这个需求是破坏性的,这时候如果步调不统一,其他项目怎么办?要么其他项目被迫升级,要么公共组件库粘贴复制一份用来满足这个独特需求。Monorepo还是更适合框架、工具类库开发,业务项目最好还是独立代码仓库的好。最后Monorepo 和 Polyrepo 都有各自的好处,项目不大就用 Polyrepo 也不会有什么坏处,当项目复杂度越来越高时,就要开始考虑做 Monorepo 整合了,让团队的工作更加聚合,让代码更加聚合。
Monorepo模式 什么是 Monorepo?一个 Monorepo 是一个单一的存储库,包含 多个不同的项目 ,和 明确的关系 。和 Monorepo 对立的是传统的 Polyrepo 模式,每个项目对应一个单独的仓库来分散管理现代的前端工程越来越多的都会选择 Monorepo 的方式进行开发,比如 Vue、React 等知名开源项目都采用的 Monorepo 的方式进行管理。Monorepo 的组织方式如下├── packages | ├── pkg1 | | ├── package.json | ├── pkg2 | | ├── package.json ├── package.json在 packages 目录下存放多个子项目,当然也可以叫其他名字,每个子项目都有自己的 package.json 文件,用来管理子包。在更换新的方式之前,一定要知道原先的方式有什么缺点。接下来就先聊聊 Polyrepo 的方式在生产上都存在着哪些弊端。Polyrepo 的弊端1. 代码重复Polyrepo 容易导致代码重复,主要是因为不同的项目都有自己的独立代码仓库。在维护一些基础组件或者工具函数时,会想着直接从 A 仓库将代码复制到 B 仓库里使用,这样很方便,但是却给后续维护成本带来了很大的负担。一旦出现需要修改的地方,需要在 多个仓库中进行修改 ,这可能会导致修改过程出现错误,并可能导致代码的不一致。那么当然我们可以不进行复制,将公共逻辑抽离出来,单独发包,作用一个 npm 模块引入到项目中,需要修改时,也只用修改一份代码,然后重新发布即可。但是这整个流程还是太复杂了,并不是完美的解决方式,仅仅是为了修改一点点东西,就需要去发包、更新,这太麻烦了。小结:不同仓库之间的割裂感、导致复用代码的成本很高,开发体验差。或者需要在多个仓库中重复编写相同的代码,从而导致代码的不一致性和冗余性。2. 版本管理因为多个仓库分别管理自己的代码,这样会缺乏一个 全局视角去看待所有仓库 ,无法清晰的了解到整个项目的结构和状态。当不同仓库中的有依赖关系时,会有依赖管理的问题,时时刻刻都需要注意依赖的版本和代码是否一致例如:主项目依赖了子项目提供的组件,如果此时子项目在某次升级时产生了 breaking change 版本,和原来的组件使用方式完全不一致,这样主项目就直接寄了。因此我们需要在子项目更新时,及时的更新主项目的依赖,这样就形成了负担。当组件出现异常时,就会开始怀疑包版本是否不正确...因此,Polyrepo 需要有合适的版本管理方法,保证版本和代码的一致性3. 工具混乱每个项目都使用自己的一组命令来运行测试、构建、服务、检查、部署等。不一致会导致记住在不同项目中使用哪些命令的心理负担。单独部署、独立工作流在多仓库情况下,由于在不同的仓库里,继承测试会变得更加的困难,需要很多步骤才能组合在一起测试。同时每个项目都使用自己的一组命令来运行测试、构建、服务、检查、部署等。不一致会导致记住在不同项目中使用哪些命令的心理负担,维护起来也是问题例如:每个项目都会配置自己的 webpack.config.js 文件,但是这些配置很多都是一致的。例如:CI、CD 流程很难将多个仓库组合到一起去,测试也比较难处理4. 代码共享要跨存储库共享代码,可能会为共享代码创建一个存储库。那么必须设置工具和 CI 环境,将提交者添加到存储库,并设置包发布以便其他存储库可以依赖它。让我们不要开始跨存储库协调第三方库的不兼容版本....5. 代码管理基于 Polyrepo 管理,每个开发人员的 commit 都会提交到各个仓库,不利于代码的 CR,也不利于管理代码合入机制,导致容易出现逃逸现象。Monorepo 能解决什么问题?Monorepo 都能解决以上的问题不仅仅在于减少了维护和管理多个代码库的成本,同时还有以下优点:代码复用 :因为多个项目共享一个代码库,所以避免了在不同项目中重复编写相同功能代码的问题,提高了开发效率。提升协作效率 :多个项目在同一个代码库中进行开发,可以方便地共享代码和文档,避免不同项目之间的沟通和协调成本。集中管理 :Monorepo 架构中,不同的应用程序都在同一个代码库中,方便管理和监控。这一点非常重要,特别是在需要同时对多个版本进行修改和维护的情况下。统一构建 :Monorepo 的一个重要特点是可以共用一套构建系统和 工具链进行构建和部署 ,提升了构建的效率。可以快速定位问题 :由于所有的代码都在同一个代码库中进行开发,debugger 可以很快找出问题所在的代码文件和行数,便于开发人员调试问题。一个版本 :无需担心因为项目依赖于第三方库的冲突版本而导致的不兼容问题。Monorepo 和 Polyrepo 的不同?前面说完之后,相信这里已经有了答案,这里再用对比的方式来看看 Monorepo 和 polyrepo 相比之下都有哪些优势依赖安装PolyrepoMonorepo每个项目都需要安装在主项目安装这里就可以看到 Monorepo 的优势在于只需一次安装,即可安装所有子项目的依赖,而 polyrepo 需要每个都单独 installCI 构建PolyrepoMonorepo各自构建增量构建:根据依赖关系(DAG),通过拓扑排序并行构建此次改动涉及到的项目Monorepo 的优势在于能够通过有向无环图,清楚的知道依赖关系,并通过拓扑排序进行增量的构建,而 Polyrepo 也有一定的优势在于无更改就不需要重新打包同时在本地开发调试、上线部署上还有着很大的优势...Monorepo 如何搭建?最简单的方式是采用 pnpm + workspace 来搭建,不需要其他额外的工具,利用 pnpm 提供 filter 命令,基本可满足大部分场景。搭建方式也很简单可以├── packages | ├── pkg1 | | ├── package.json | ├── pkg2 | | ├── package.json ├── package.json ├── pnpm-workspace.yaml在 pnpm-workspace.yaml 中指定 packages 的入口packages: # all packages in subdirs of packages/ and components/ - 'packages/**'在 pkg1 中引用 pkg2 只需要在 pkg1 的 package.json 中的依赖中进行添加"dependencies": { "@test/utils": "workspace:^1.0.0" }在根的 package.json 中通过 filter 配置 script 来指定特定的项目执行"build:pkg1": "pnpm --filter=@pkg1 build",当你的项目需要根据 package.json 下的依赖进行拓扑排序并行打包、增量打包、打包缓存、依赖图可视化等等各种功能时,你可以考虑一些构建工具比如 Rush、lerna、Turbo,这些都能高效的帮你完成想要的工作Monorepo的弊端:用Monorepo之前想一想:1.团队能否驾驭?大仓开发意味着团队每个人有全部项目的代码权限,严格的CR机制,自动化构建、测试流水线、团队整体代码水平这些都得有一定规模和经验。试想某个周五的下午一个公司新人提交了一段神秘代码,然后周末整个公司的项目全都挂了2.产出是否步调一致?无论是react还是vue他们采用Monorepo更多是因为他们产出步调一致并且存在相互关联场景,合在一起也能作为一个单独的项目发布。但是在普遍的业务项目开发中产出基本都是独立的项目,没有太多联系。例如,多个项目共用一个组件,如果有一天项目A对该组件有独特需求,这个需求是破坏性的,这时候如果步调不统一,其他项目怎么办?要么其他项目被迫升级,要么公共组件库粘贴复制一份用来满足这个独特需求。Monorepo还是更适合框架、工具类库开发,业务项目最好还是独立代码仓库的好。最后Monorepo 和 Polyrepo 都有各自的好处,项目不大就用 Polyrepo 也不会有什么坏处,当项目复杂度越来越高时,就要开始考虑做 Monorepo 整合了,让团队的工作更加聚合,让代码更加聚合。 -
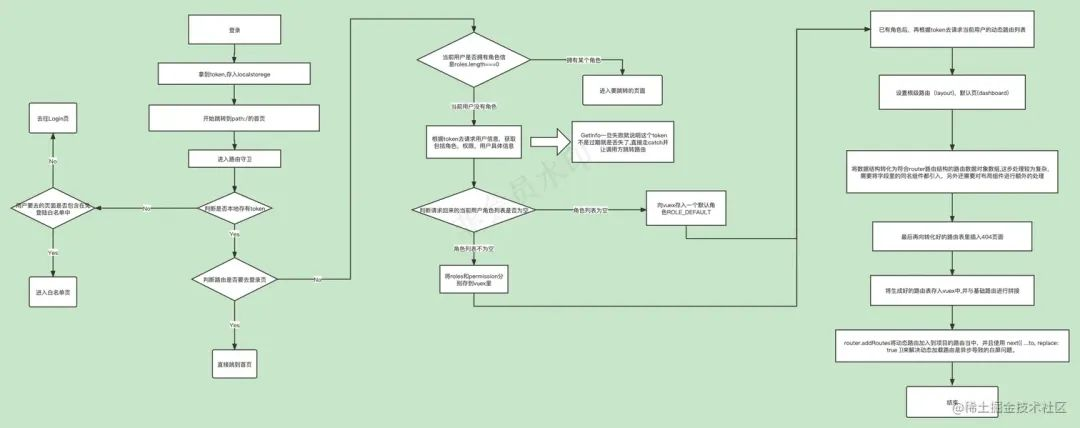
前端权限开发——设计到实践 做后台项目区别于做其它的项目,权限验证与安全性是非常重要的,可以说是一个后台项目一开始就必须考虑和搭建的基础核心功能。在后台管理系统中,实现权限控制可以采用多种方案:权限方案类型描述基于角色的访问控制(Role-Based Access Control,RBAC)是一种广泛采用的权限控制方案。系统中定义了不同的角色,每个角色具有一组权限,而用户被分配到一个或多个角色。通过控制用户角色的分配,可以实现对用户访问系统中不同功能和资源的权限控制。基于权限的访问控制(Permission-Based Access Control)这种方案将权限直接分配给用户,而不是通过角色来管理。每个用户都有自己的权限列表,控制用户对系统中各项功能和资源的访问。基于资源的访问控制(Resource-Based Access Control,RBAC)这种方案将权限控制与资源本身关联起来。系统中的每个资源都有自己的访问权限,用户通过被授予资源的访问权限来控制其对资源的操作。层次结构权限控制(Hierarchical Access Control)这种方案基于资源和操作的层次结构来进行权限控制。系统中的资源和操作被组织成层次结构,用户被授予访问某个层次及其子层次的权限。基于规则的访问控制(Rule-Based Access Control)这种方案使用预定义的规则来确定用户对系统中功能和资源的访问权限。规则可以基于用户属性、环境条件或其他因素进行定义。这里我选择了基于角色的访问控制(Role-Based Access Control,RBAC) 这是因为RBAC提供了一种灵活且易于管理的方式来控制用户对系统功能和资源的访问,也是目前最主流的前端权限方案选择。在RBAC中,系统中的功能和资源被组织成角色,而用户则被分配到不同的角色。每个角色都有一组权限,定义了该角色可以执行的操作和访问的资源。通过给用户分配适当的角色,可以实现对用户的权限控制。RBAC的好处之一是它简化了权限管理的复杂性。管理员只需管理角色和分配角色给用户,而不需要为每个用户单独定义权限。当需要对用户的权限进行修改时,只需调整其角色的权限即可。此外,RBAC还支持灵活的权限组合,允许创建具有不同权限组合的角色,以适应不同用户的需求。它也便于扩展,可以随着系统的发展和需求的变化而调整和添加角色。2.RBAC下的权限字段设计与管理模型1.用户权限授权是对用户身份认证的细化。可简单理解为访问控制,在用户身份认证通过后,系统对用户访问菜单或按钮进行控制。也就是说,该用户有身份进入系统了,但他不一定能访问系统里的所有菜单或按钮,而他只能访问管理员给他分配的权限菜单或按钮。主要包括:Permission(权限标识、权限字符串):针对系统访问资源的权限标识,如:用户添加、用户修改、用户删除。Role (角色):可以理解为权限组,也就是说角色下可以访问和点击哪些菜单、访问哪些权限标识。权限标识或权限字符串校验规则:权限字符串:指定权限串必须和菜单中的权限标识匹配才可访问权限字符串命名规范为:模块:功能:操作,例如:sys:user:edit使用冒号分隔,对授权资源进行分类,如 sys:user:edit 代表 系统模块:用户功能:编辑操作设定的功能指定的 权限字符串与当前用户的 权限字符串进行匹配,若匹配成功说明当前用户有该功能权限还可以使用简单的通配符,如 sys:user:*,建议省略为 sys:user(分离前端不能使用星号写法)举例1 sys:user 将于 sys:user 或 sys:user: 开头的所有权限字符串匹配成功举例2 sys 将于 sys 或 sys: 开头的所有权限字符串匹配成功 这种命名格式的好处有:可读性和可理解性 :使用模块、功能和操作的格式可以直观地表达权限的含义。每个部分都有明确的作用,模块表示特定的模块或子系统,功能表示模块内的某个功能或页面,操作表示对功能进行的具体操作。通过这种格式,权限名称可以更容易地被开发人员、管理员和其他人员理解和解释。可扩展性和灵活性: 通过使用模块、功能和操作的格式,可以轻松地扩展和管理权限。每个模块、功能和操作都可以被单独定义和控制。当系统需要增加新的功能或操作时,可以根据需要添加新的权限字符串,而不需要修改现有的权限规则和代码。细粒度的权限控制: 这种格式支持细粒度的权限控制,可以针对特定的功能和操作进行权限管理。通过将权限名称拆分为模块、功能和操作,可以精确地定义哪些用户或角色具有访问或操作特定功能的权限。避免权限冲突: 使用模块、功能和操作的格式可以避免权限之间的冲突。不同模块、功能和操作的权限名称是唯一的,这样可以避免同名权限之间的混淆和冲突。2.权限管理模型关键数据模型如下:用户:登录账号、密码、角色角色:角色名称、角色权限字符、对应菜单、对应菜单下的权限菜单:菜单名称、菜单URL、菜单类型用户角色关系:用户编码、角色编码角色菜单关系:角色编码、菜单编码关系图如下:【用户】 <---多对多---> 【角色】 <---多对多---> 【菜单/权限】3.实现思路与步骤前端权限一般分为路由级权限和按钮级权限,这里我们先实现页面路由级的权限功能,按钮级的会在后面讲到。大致的思路如下图:上图是用户从 登录-->路由守卫-->权限验证-->构建路由表-->跳转目标页面的一个简单的正向流程,可以看到,权限验证和 构建路由表这两步是发生在 路由守卫这一步里,而实际上在开发设计阶段,我们还要做的准备有:与后端确认权限字段及类型确定路由表信息是由前端还是后端生成为了方便理解,我们就按照这个正向流程来逐步实现,期间需要用到或者提前考虑设计到的内容,包括以上需要准备的两点,我会补充在步骤当中。1.登录登录成功后,获取到token,将token存到本地的sessionStorage里。async login({ commit }, userInfo) { const { data } = await login(userInfo) const accessToken = 'Bearer ' + data.access_token if (accessToken) { sessionStorage.getItem(tokenTableName) } else { message.error(`登录接口异常,未正确返回${tokenName}...`) } }接着,进行路由跳转到首页import { useRouter } from 'vue-router'; const router = useRouter(); router.push('/');如果考虑到页面token失效后,重新登陆后返回原先的路由地址,则需要在路由守卫中添加 redirect字段用来存储当前的路由地址 next({ path: '/login', query: { redirect: to.fullPath }, replace: true })然后在登录页中,监听路由对象中的这个值,如果有值,那么在刚刚路由跳转时,就跳转到该路由地址,而非 /首页,另外,还需要考虑到403,404页面。所以,添加了这些逻辑后,部分代码如下://login.vue <script setup> import { ref, watch, useRouter } from 'vue'; import { useRouter } from 'vue-router'; const redirect = ref('/'); const router = useRouter(); watch( () => router.currentRoute.value.query.redirect, (redirectValue) => { redirect.value = redirectValue || '/'; }, { immediate: true } ); function handleRoute() { return redirect.value === '/404' || redirect.value === '/403' ? '/' : redirect.value }, async handleSubmit() { loading.value = true try { await login(form.value) loading.value = false router.push(handleRoute()); } catch { loading.value = false } }, </script>2.路由守卫与权限校验当进行路由跳转时,会进入到路由守卫中,在路由守卫中:路由守卫会首先判断有没有token,如果没有,先判断要去的路由地址是否包含在路由白名单内,如果要去的路由地址也不在路由白名单内,就会让用户跳转到登录页重新登陆。如果有token,会先判断跳转的目标地址是否是登录页,如果是,则重新跳转到默认首页此时,我们就需要对用户权限进行校验,首先,判断当前用户是否 拥有角色信息,如果没有,就要获取用户的角色信息。3.获取角色信息与权限信息调取用户信息接口获取用户角色信息和权限信息,代码如下://store/user // 获取用户信息 GetInfo({ commit, dispatch }) { return new Promise((resolve, reject) => { getUserInfo() .then(async (response) => { const result = response.data if (result.roles && result.roles.length > 0) { // 验证返回的roles是否是一个非空数组 commit('SET_ROLES', result.roles) //permissions就是对应的用户权限信息 commit('SET_PERMISSION', result.permissions) } else { // 如果当前用户没有角色,则赋值一个默认角色 commit('SET_ROLES', ['ROLE_DEFAULT']) } resolve(result) // GetInfo一旦失败就说明这个token不是过期就是丢失了,直接走catch并让调用方跳转路由 if (!response.success) { reject(response.errorMsg) } }) .catch((error) => { reject(error) }) }) },根据之前上文提到的权限管理模型,从之间的关系是多对多,因此,role(角色)和 permssions(权限)的类型应为数组,其中的权限permssion这个字段的格式规范也在上文提及。在与后端约定好后,后端返回的信息如图:4.谁来生成动态路由表?在成功获取到用户信息,拿到用户角色和对应权限后,此时,就需要根据权限生成对应的路由表了,到这里,我们需要思考一个问题: 路由表是由后端提供还是由前端提供? A:前端根据权限生成路由表B:后端生成路由表给前端没错!答案是C:路由表可以由后端提供或由前端提供。两者的优劣分别是:1、后端提供路由表:优点 :安全性高:后端负责验证和控制权限,可以确保只有授权的用户能够访问特定的路由和功能。隐藏敏感信息:后端可以根据用户的角色和权限隐藏不应该被访问的敏感路由和数据。适用于复杂的权限规则:后端可以使用更复杂的逻辑和规则来处理权限控制,例如基于用户角色、用户组、权限等的复杂控制逻辑。缺点:前后端耦合度高:由于路由表由后端提供,前端开发人员可能需要与后端开发人员密切协作,增加了协调和沟通的成本。前端依赖后端:前端应用程序可能需要等待后端提供路由表后才能进行开发和测试,增加了开发的时间和依赖性。2、前端提供路由表:优点:前后端解耦:前端可以独立开发和维护路由表,减少了与后端的依赖性和协调成本。更好的用户体验:前端可以根据用户的角色和权限动态展示路由和功能,提供更灵活和个性化的用户体验。缺点:安全性较低:前端提供的路由表容易受到篡改和绕过,安全性相对较低。隐藏敏感信息的难度增加:前端无法直接隐藏敏感路由和数据,需要依赖后端接口的授权验证来保护敏感信息。最终,考虑到后台管理系统的安全性优先级最高,我选择了由后端存储,并生成返回路由表信息。 确定好了之后,你就会遇到一个坑:后端提供的路由表无法直接在前端路由中添加使用 这是因为,后端存储的路由表的结构只一个JSON对象。怎么解决,我们放到后面讲。5.公共路由和动态路由我们现在把整个路由分为两个部分,分别是 公共路由和 动态路由(私有路由)。公共路由公共路由顾名思义就是无论当前用户是什么角色,都会出现的路由部分。一般这样的路由分别有:首页驾驶舱、登录注册页、403页、404页。 这部分路由是在前端项目中提前写死的。 以我的项目为例,我在src/config下创建一个 publicRouter.js文件,然后里面放入基础路由信息://基础公共路由 export const constantRouterMap = [ { path: '/', name: '', component: () => import('@/layout'), redirect: '/homePage', children: [ { path: '/homePage', name: 'homePage', component: () => import('@/views/homePage/index.vue'), }, ], }, { path: '/login', component: () => import('@/views/login'), }, { path: '/403', name: '403', component: () => import('@/views/403'), }, { path: '/:pathMatch(.*)*', component: () => import('@/views/404'), }]这里面都是路由懒加载的写法,这个没啥好说的。需要注意的是在vue3中,vue-router的版本是4.x以上,在跳转404页面时,如果你的写法是{ path: "/404", name: "notFound", component: () => import('@/views/404') }这样写会提示报错,这是因为vue-router4.x的版本官方推荐引入了这种新写法,配置一个通配符路由,匹配所有未被其他具体路由匹配的路径。其中 :pathMatch 是参数名,而 (.*)* 是参数的匹配模式,它使用正则表达式来匹配任意路径。动态路由(私有路由)上文提到的后端返回给前端当前用户的路由表信息,其实就是私有路由,这部分的路由是动态的。那么我们只需要把 公共路由+动态路由=当前角色用户完整路由表。然鹅, 后端返回给前端的动态路由是无法直接添加到当前页面路由中的 ,这是因为在浏览器的前后端请求当中,信息的返回体都是以JSON字符串的数据交换格式进行传输,而JSON字符串是不支持函数的。为什么要提到函数形式呢?因为当我们在路由表使用懒加载的写法时,component的值是一个异步函数。也只有异步函数才能实现对路由的异步懒加载。import()会返回一个promise,这个 promise 最终会加载对应的组件模块。在格式上表现为一个func函数,因此,我们无法将compnent的值传给后端存储但是办法总比困难多,我们可以将对应的路径字符串传给后端存储,然后再通过后端返回的路径字符串转换成这种箭头函数的写法。除了这个需要转换以外,我们还要考虑一些问题:比如,转换后的路由结构要符合router中的路由格式,否则会在调用router.addRoutes时报错,添加失败。添加一些其他自定义属性(例如添加导航栏菜单图标、某个路由的显隐、路由缓存、跳转外链接、...),以满足特定需求。以我项目中的的路由示例,直接上代码看:{ "path": "/", //path,路由的路径,即访问该路由时的 URL 路径。 "name": "homePage",//name,路由的名称,用于在代码中标识路由。通常用于编程式导航。 "hidden": false,//hidden,是否隐藏路由,在Vue Router 4.0 中被废弃。 "component": "Layout"//路由对应的组件,可以是通过懒加载方式导入的异步组件,或直接引入的同步组件。 "meta": {//meta,路由元信息,可以用于存储一些额外的信息,比如页面标题、权限等 "title": "首页", //路由标题 "icon": "icon-Home", //路由图标 "target": "", //是否跳转新页签 "permission": "homePage",//权限 "keepAlive": false//是否缓存 }, "redirect": "/homePage",//重定向 "fullPath": "/",//完整的url路径,会带上?后面的参数 "children": [//子路由 { "path": "/homePage", "name": "homePage", "meta": { "title": "首页", "icon": "", "target": "", "permission": "homePage", "keepAlive": false }, "fullPath": "/homePage" } ] }考虑完这些之后,我们就开始拿着后端返回的路由表信息动手转换吧! 先看看后端返回给前端的路由表格式内容这里你只需要注意component这个字段的值就行了。可能有人会问: “那我给后端传的路由表是什么格式的,也是这样吗?” 答案是:当然不是!RBAC权限方案中,用户可以自己配置权限,也就是会有对应的用户管理,角色管理,菜单(权限)管理这三个基本的模块,给后端传的是对应模块的修改配置内容。前端是不需要关心传给后端什么格式。 有点啰嗦了,总之,就是你指着上文这三张图片,让后端给你生成出来就完事了。后端要是说办不到,那就是后端的问题。6.RBAC的权限配置项上文提到了三个基本的配置模块,分别是 用户管理,角色管理,菜单(权限)管理,按照先后顺序,我们首先要新建一个权限,在页面级的权限中,权限是跟每个页面路由一一对应的,所以当我们需要新建一个权限的时候,也就是在新建一个页面路由。而为了方便知道所有页面权限之间的层级关系,最终的展现形式就是一个 树形表格结构 :可以看到,在页面路由(权限)配置项里,单个路由的各个都可以进行修改配置,这就让整个项目的路由表的可维护性和灵活度都极大的提高。需要注意的是 路由地址和 组件路径这两个配置项,路由地址可以随意命名,但是 同层级下,必须唯一 。而组件路径里面的值就是 相对src目录的相对路径 。比如我新建一个部门管理页面权限,一般在前端路由中的懒加载写法是这样:component: () => import('@/views/login'),但在这个配置项中,只需要填入login这个字段就行了。原因是因为前面的这些字段会在后面对路由的格式化中进行处理。虽然后续步骤会讲到这一步,但这里我还是先贴出来,方便你理解:component: constantRouterComponents[item.component || item.key] || (() => import(`@/views/${item.component}`).catch(() => import('@/views/404') )),那有人就会问,如果我乱填一个不存在的组件路径地址怎么办?正常情况下这样会导致整个动态路由在构建过程中报错,从而导致白屏。所以,上述代码里的 .catch会捕获这个错误,然后跳转到404页面,再从404页面跳转到首页。当我们配置好权限后,会将新增的路由配置信息发送给后端, 后端根据这些配置信息,会在对应的路由表中添加这个路由,并生成新的路由表返回给前端 。那当我们有一个权限之后,该怎么配置给对应的用户呢?还记得我上文提及的RBAC的权限管理模型嘛:就是按照关系图中,我们将权限分配给角色,所以,就要有 角色管理这个模块来进行分配:用户管理也是依葫芦画瓢,跟 角色管理如出一辙,碍于篇幅,就不再过多赘述。每一个配置项都可以根据你的业务场景和需要,进行增减。7.获取动态路由(私有路由)并转换言归正传,接下来,这一步是整个前端权限中最重要的一步。在src/router下,我们新建一个generatorRouters.js文件。里面的内容是://getCurrentUserNav获取动态路由的接口 import { getCurrentUserNav } from '@/api/user' //validURL是一个正则判断方法,用来校验当前字符串是否符合url外链格式 import { validURL } from '@/utils/validate' // 前端路由表 const constantRouterComponents = { // 基础页面 layout 必须引入 Layout: () => import('@/layout'), 403: () => import('@/views/403'), 404: () => import('@/views/404'), } /** * 动态生成菜单 * @param token * @returns {Promise<Router>} */ export const generatorDynamicRouter = (token) => { return new Promise((resolve, reject) => { getCurrentUserNav() .then((res) => { //接收后端返回的路由表,结构是个数组 let menuNav = res.data //将路由表存到本地临时缓存中 //这一步是为了刷新的时候不需要再调接口,增加用户体验的,没这方面需求可以不用写 sessionStorage.setItem('generateRoutes', JSON.stringify(menuNav)) //转化路由格式 const routers = generator(menuNav) resolve(routers) }) .catch((err) => { reject(err) }) }) } /** * 格式化树形结构数据 生成 vue-router 层级路由表 * * @param routerMap //当前路由表route * @param parent//当前路由表route的父级component * @returns {*} */ export const generator = (routerMap, parent) => { return routerMap.map((item) => { const { title, show, hideChildren, hiddenHeaderContent, icon, hidden } = item.meta || {} if (item.component) { // Layout ParentView 组件特殊处理 //这里是对父组件/布局组件的处理,因为有可能出现嵌套布局和多种布局的情况,这个时候需要进行处理。 if (item.component === 'Layout') { item.component = 'Layout' } else if (item.component === 'ParentView') { item.component = 'BasicLayout' item.path = '/' + item.path } } if (item.isFrame === 0) { item.target = '_blank' } const currentRouter = { // 如果路由设置了 path,则作为默认 path,否则 路由地址 动态拼接生成如 /dashboard/workplace path: item.path || `${(parent && parent.path) || ''}/${item.key}`, // 路由名称,建议唯一 // name: item.name || item.key || '', name: item.name || item.key || '', // 该路由对应页面的 组件 :方案1 // 该路由对应页面的 组件 :方案2 (动态加载) //这里就是将component的字符串值转换成懒加载的异步函数 //同时,如果当前路径并没有对应的组件,catch捕获报错,然后跳转到404页,这一步很重要,否则 component: constantRouterComponents[item.component || item.key] || (() => import(`@/views/${item.component}`).catch(() => import('@/views/404') )), hidden: item.hidden, // redirect: '/' + item.path || `${parent && parent.path || ''}/${item.key}`, // meta: 页面标题, 菜单图标, 页面权限(供指令权限用,可去掉) meta: { title: title, icon: icon, hiddenHeaderContent: hiddenHeaderContent, target: validURL(item.path) ? '_blank' : '', permission: item.name, keepAlive: false, hidden: hidden, }, //适配本框架的跳转路径 } // 是否设置了隐藏菜单 if (show === false) { currentRouter.hidden = true } // 修正路径,而antdv-pro的pro-layout要求每个路径需为全路径 //这一步的修正路径也是因人而异,正常情况下按照我这样拼接就没问题了 if (!constantRouterComponents[item.component || item.key]) { if (parent && parent.path && parent.path !== '/') { currentRouter.path = `${parent.path}/${item.path}` } } // 是否设置了隐藏子菜单 if (hideChildren) { currentRouter.hideChildrenInMenu = true } // 重定向 item.redirect && (currentRouter.redirect = item.redirect) //添加fullPath currentRouter.fullPath = currentRouter.path // 是否有子菜单,并递归处理 if (item.children && item.children.length > 0) { currentRouter.children = generator(item.children, currentRouter) } return currentRouter }) }generatorDynamicRouter方法(promise嵌套)上面的代码有点多,不要觉得麻烦,其实就两个方法,第一个方法 generatorDynamicRouter会调取后端接口, 获取后端返回的私有路由表信息 ,返回的是个 promise对象,因为需要调接口请求后端数据,并且其他方法依赖这个方法的接口返回值,所以是个异步函数。之所以这么写的另外一个原因,是因为在它之前还有个promise异步方法包着它。我们都知道:在嵌套的 Promise 中,内部的 Promise 会先执行,然后再执行外部的 Promise。这是由于 JavaScript 的异步执行机制所决定的。 所以这种套娃式的目的只有一个—— 就是确保外层的异步方法在调用内部异步方法时,能够保证拿到内部异步方法请求成功之后的返回值 (也就是将异步方法变成同步方法,这也是Promise主要的作用之一,面试常问的)。而最外层的异步方法,是放在路由守卫当中直接调用的,由于我们是动态异步加载路由,那么执行的方法肯定也是异步。具体的原因是因为:如果动态加载路由的方法不是异步的,那么在路由守卫中使用它将导致它立即执行并返回一个 Promise,而不是在路由导航过程中延迟加载。这样会使得在路由守卫中的逻辑无法按预期执行,因为在组件加载完成之前,它依赖的组件可能还没有被加载,导致出现错误或不一致的状态。从后端获取路由配置往往涉及到网络请求和异步操作,不能保证立即返回所有路由信息。当你从后端获取到路由配置后,需要将其添加到 Vue Router 中,以便在前端应用程序中进行动态路由。在这个过程中,你需要使用异步操作来确保在获取到路由配置后再添加到路由中。generator方法(递归转化)言归正传,generatorDynamicRouter方法调取后端接口,拿到后端返回路由表信息后,会紧接着调用第二个 generator方法,并将路由表信息当做参数传入。而 generator是一个递归方法。这个也很好理解,因为路由信息里都会包含children子路由,需要层层递归,generator内部会对每一个路由进行 逐层转化 ,每一步都在代码中标有注释,我就不再过多赘述了。我们只需要知道:generator的最终目的就是将后端返回的路由表结构转化成符合前端路由格式的路由(听起来有点绕)。附上格式化好之后的路由信息:再对比下格式化之前的样子:可以看到component从字符串变成了函数,path路径也得到了拼接补充。8.存储格式化好的动态路由及导航栏菜单信息上文提到在generatorDynamicRouter异步方法之外还有一层异步方法,其实我是放在了vuex的store下某个模块中的actions里(默认大家都会用vuex)。具体代码如下const actions = { GenerateRoutes({ commit }) { let sidebarList = [] return new Promise((resolve) => { generatorDynamicRouter().then((routers) => { //sidebarList是侧边栏渲染数据 sidebarList = routers //routers就是我们要存储到vuex中的动态路由 commit('set_routers', routers) //侧边栏数据存到vuex中 commit('set_sidebarList', sidebarList) resolve() }) }) }, }9.添加动态路由好了,到这一步,我们就拿到了准备好的 公共路由和 私有路由。这个时候,我们再回到路由守卫,回顾一下之前的流程:路由守卫先判断token没有token去登录拿token(或者是直接去了白名单里)拿到token后判断有没有角色信息,没有角色信息就去请求角色信息(调接口)拿到角色信息后,再去获取对应角色信息的路由表(调接口)将后端返回的路由表信息转换成前端能添加的路由表信息格式添加路由跳转对应路由页面现在,我们来到了第6步,添加路由,在添加路由之前,先看下路由守卫:路由守卫的代码如下,在src/config目录下新建文件 permissions.js import router from '@/router' import store from '@/store' import getPageTitle from '@/utils/pageTitle' import getInfoRouter from '@/router/getInfoRouter' import { loginInterception, recordRoute, routesWhiteList } from '@/config' router.beforeEach(async (to, from, next) => { let hasToken = store.getters['user/accessToken'] if (hasToken) { if (to.path === '/login') { next({ path: '/' }) } else { //权限校验 if (store.getters['user/roles'].length === 0) { try { //获取用户信息,包括角色信息和权限信息 await store.dispatch('user/GetInfo') //获取动态路由表信息,并对路由表进行格式转化,然后存到vuex中 await store.dispatch('async-router/GenerateRoutes') //从vuex中拿到动态路由表数据 let accessRoutes = store.getters['async-router/addRouters'] //循环添加路由 accessRoutes.forEach((route) => { //isHttp方法用来判断是否是外链,如果是外链,就不添加到当前路由表中 if (!isHttp(route.path)) { router.addRoute(route) // 动态添加可访问路由表 } }) //刷新跳转 next({ ...to, replace: true }) } catch (e) { //登出 await store.dispatch('user/Logout') //记录登出前的路由地址 next({ path: '/login', query: { redirect: to.fullPath } }) } } else { next() } } } else { //判断是否在白名单中 if (routesWhiteList.indexOf(to.path) !== -1) { next() } else { //记录跳转到登录页之前的路由地址 next({ path: '/login', query: { redirect: to.fullPath }, replace: true }) } } }) router.afterEach((to) => { //浏览器页签标题 document.title = getPageTitle(to.meta.title) })在vue-router4.x版本中 ,往当前的路由 router对象中动态添加路由时,需要使用官方提供的 addRoute方法,不能直接对router对象进行修改,这是因为vue-router必须是要vue在实例化之前就挂载上去的。addRoute方法传入的参数是 单个路由对象 ,所以写法上我们需要对动态路由数组进行for循环,在内部调用 addRoute方法,从而达到成功添加多个动态路由的目的。这里附上官方API地址链接:router.vuejs.org/zh/api/inte…添加完路由之后,调用 next({ ...to, replace: true }),就会成功跳转到目标路由地址了。10.登出当用户要退出时,也就是登出,我们只需要调用登出接口,并在接口成功返回后,重置vuex中的用户信息(token,角色roles,权限permission),同时清空本地缓存的数据就行了。附上代码:/** * @description 退出登录 * @param {*} { dispatch } */ Logout({ commit, dispatch, state }) { return new Promise((resolve, reject) => { logout() .then(async () => { await dispatch('resetAll') //清空导航tab页签 this.dispatch('tagsBar/delAllVisitedRoutes', { root: true }) resolve() }) .catch((error) => { reject(error) }) .finally(() => {}) }) }, /** * @description 重置accessToken、roles、permission等 * @param {*} { commit, dispatch } */ async resetAll({ dispatch, commit }) { await dispatch('setAccessToken', '') commit('SET_ROLES', []) commit('SET_PERMISSION', []) sessionStorage.clear() },到这一步,整个前端权限的流程就算是走完了。4.按钮级权限前端按钮级权限,是指在前端界面中,根据用户的权限不同,对不同的按钮进行权限控制。这样做的目的是为了确保系统的安全性和数据的保密性,使得不同用户只能执行其有权执行的操作,从而避免潜在的安全风险。上面这段定义是我copy过来的,其中这句 对不同的按钮进行权限控制并不完全对, 除了按钮,比如页面中的某个字段,某个div,某个组件要求根据当前用户的权限进行控制时,都可以称为按钮级权限 。像这种按钮级权限的设计方案很多,在vue中,本人目前知道的主流方式有两种:条件渲染(Conditional Rendering): 这是一种简单有效的方法,通过在前端代码中根据用户的权限信息来决定是否渲染特定的按钮或组件。比如,你可以使用条件语句(如 v-if、ngIf等)来判断用户是否有权限,从而决定是否渲染按钮。指令/组件封装: 使用一些前端框架(如Vue、React、Angular)提供的自定义指令或组件,可以封装权限控制逻辑。你可以创建一个自定义指令或组件,接受用户权限作为输入,然后根据权限来决定是否显示按钮。一开始我用的是指令封装的方式,但是随着业务需要,条件渲染这种方式我也用了。在开始看具体的实现方法之前,不知道你有没有留意到上文的路由守卫中,只是根据用户的角色字段 role来校验当前用户的权限,还有一个字段 permssions(权限)其实一直没有派上用场,但是无论是在权限的配置项中,还是在后端的返回字段里,都有它的存在:1.指令/组件封装形式的按钮级权限现在它的作用来了,先看指令的具体实现方式,我们在src/directive目录下新建一个 hasPermi.js文件,代码如下:/** * v-hasPermi 操作权限处理 */ import store from '@/store' export default { //`el`(element):这是指令所绑定的元素,是一个普通的DOM元素。在自定义指令的钩子函数中, //你可以通过操作`el`来实现对元素的各种修改,比如添加、删除、修改样式等。 /** `binding`:这是一个包含指令信息的对象。它包括了以下属性: `name`:指令的名称,不包括`v-`前缀。 `value`:指令的绑定值,即传递给指令的参数。在你的示例中,`value`存储了操作权限的标识符数组。 `oldValue`:先前的绑定值,仅在组件更新时可用。 `expression`:指令的表达式,如`v-my-directive="someValue"`中的`someValue`。 `arg`:指令的参数,如`v-my-directive:arg="value"`中的`arg`。 `modifiers`:一个包含修饰符的对象,如`v-my-directive.modifier`。 `vnode`:渲染该组件的虚拟节点。 */ mounted(el, binding, vnode) { const { value } = binding //all_permission代表所有权限,一般超级管理员需要用这个 const all_permission = '*:*:*' //获取后端返回的权限字段列表 const permissions = store.getters && store.getters['user/permissions'] //校验当前用户的权限列表是否存在 if (value && value instanceof Array && value.length > 0) { //传入的参数,需要校验的权限字段值 const permissionFlag = value //判断当前权限列表中,有无该传入的权限字段值 const hasPermissions = permissions.some((permission) => { return ( all_permission === permission || permissionFlag.includes(permission) ) }) if (!hasPermissions) { // 如果用户没有权限,移除当前元素的父节点(即移除当前元素) el.parentNode && el.parentNode.removeChild(el) } } else { throw new Error(`请设置操作权限标签值`) } }, }这段代码主要是在页面元素的挂载阶段(mounted钩子)检查用户权限,如果用户没有操作权限,那么就移除对应的页面元素。具体的代码说明我都放在里注释里。 写好了这个方法后,需要将该指令挂载到全局当中,这个时候需要进入 main.js文件,在vue3中,给vue对象挂载自定义指令的方式如下:import { createApp } from 'vue' import App from './App' import directive from '@/directive' // directive const app = createApp(App) app.mount('#app') // 添加到全局 directive(app)然后,在你需要进行按钮级权限校验的地方添加上这段指令,比如:<a-button type="primary" @click="openModal('add')" v-hasPermi="['system:user:add']" > 新增 </a-button>上面这段代码里的 system:user:add意思是 系统目录下用户管理模块的新增按钮权限 (如果看不懂就翻到文章最开始介绍RBAC的权限字段设计那里),当后端返回的当前用户数据中的permissions字段里,没有 system:user:add这个权限字段时,这个按钮就不会显示出来。2.条件渲染形式的按钮级权限自定义指令实现的按钮级权限并不能满足我的业务需要,由于vue的限制,我们的自定义指令只能用在组件的 template模块内,也就是只能放在dom标签上。但是有的时候,我可能需要对某个字段的逻辑,或者根据角色的不同,显示不同的表格列,这是数据上的处理,这个时候自定义指令就毫无用武之地。所以就需要用到条件渲染的形式。 条件渲染的形式,说白了,就是封装一个 全局方法,方法返回值是 true或者是 false,然后再加一个 v-if,但是我其实用不到这个 v-if,我只需要这个判断权限的返回结果就足够了,核心逻辑跟自定义指令如出一辙。就不再过多赘述,直接上代码你就懂了:/** * checkPermi 操作权限处理 */ import store from '@/store' export default function checkPermi(value) { const all_permission = '*:*:*' const permissions = store.getters && store.getters['user/permissions'] const permissionFlag = value const hasPermissions = permissions.some((permission) => { return all_permission === permission || permissionFlag.includes(permission) }) return hasPermissions }跟上面的自定义指令不能说完全一样,只能说是一模一样。然后,我们就需要把这个方法挂载到全局,这里的挂载方式是 vue3的:import { createApp } from 'vue' import App from './App' const app = createApp(App) app.config.globalProperties.$checkPermi = checkPermi app.mount('#app')然后在你需要用的地方引入:... <script setup> import { ref, reactive, onMounted, watch, toRefs, nextTick, getCurrentInstance, } from 'vue' const { $checkPermi } = getCurrentInstance().appContext.config.globalProperties if ($checkPermi(['ProductionManagement:CustomOrderManagement:pro'])) { //有这个按钮级权限时的处理 }else{ //没有这个按钮级权限时的处理 } </script>怎么样,是不是很简单?5.遇到的坑这里面有几个坑需要注意下:第一个坑就是在 vue3支持的vue-router4.0版本之前,也就是 vue2中,动态添加路由的方式支持的是 addRoutes,它的参数是格式是一个 数组。而到了4.0后,addRoutes这个方法被废弃,取而代之的是 addRoute,它的参数则是一个路由对象。这两个方法无论是在 传参类型还是添加相同path时的覆盖逻辑都不相同。第二个坑就是无论是用控制台还是打断点的方式,或者是用Vue.js devtools的谷歌插件,都无法在路由守卫中获取到添加完成后的最新router对象, 也就是说你会在调试addRoute加载后的动态路由表时,发现与之前为添加路由时的路由表是一样的,从而无法判断是否动态路由添加成功 (就很蛋疼)第三个坑是 next({ ...to, replace: true })这个方法,当添加好动态路由后,如果不这么写next,会白屏。 在 addRoute()之后第一次访问被添加的路由会白屏,这是因为刚刚 addRoute()就立刻访问被添加的路由,然而此时 addRoute()没有执行结束,因而找不到刚刚被添加的路由导致白屏。因此需要从新访问一次路由才行。 具体原因见文章链接:https://blog.csdn.net/qq_41912398/article/details/109231418退出后,新的用户会访问到原本不属于该用户的路由,必须刷新页面才会正常。后来通过排查,导致这个问题的原因是因为当用户登出时,当前路由router对象还保留着上一个用户的动态路由,因次,还需要在登出的时候,对路由router对象进行初始化。我们在src/router目录下的 index.js文件里写一个初始化方法://初始化路由 export function resetRouter() { //获取当前路有对象 let routers = router.getRoutes() //剔除动态路由 routers.map((it) => { if (!['login', '403', ':pathMatch(.*)*'].includes(it.name)) { router.removeRoute(it.name) } }) }然后在登出的地方引用这个方法并执行import { resetRouter } from '@/router/index.js' async logout() { resetRouter() await store.dispatch('user/Logout') this.$router.push('/login') },还有一个关于vuex的问题,从之前的代码里不难看出,我们将用户信息,角色、权限、动态路由等都存在了vuex中。 由于vuex的特性,用户会在刷新页面后,vuex里的数据会被清空,这个时候就会导致页面直接跳转到登录页 。这肯定是不能接受的,因此,我们需要对vuex里的数据在刷新的时候做持久化处理。逻辑也很简单,监听页面刷新事件,beforeunload这个方法恰好就能做到,在页面刷新的时候,将vuex中的数据缓存到浏览器本地临时缓存中,然后再在页面初始化的时候,从本地临时缓存中取出存入vuex对象中。 附上代码:(项目根目录下的的App.vue文件中,这里是vue2的写法)created() { //在页面加载时读取sessionStorage里的状态信息 sessionStorage.getItem('userMsg') && this.$store.replaceState( Object.assign( this.$store.state, JSON.parse(sessionStorage.getItem('userMsg')) ) ) //在页面刷新时将vuex里的信息保存到sessionStorage里 window.addEventListener('beforeunload', () => { sessionStorage.setItem('userMsg', JSON.stringify(this.$store.state)) }) },这里再附上src/router目录下的 index.js代码,方便大家理解路由这块:import { createWebHistory, createRouter, useRouter } from 'vue-router' import { constantRouterMap } from '@/config/router.config.js' import { generator } from '@/router/generatorRouters' const router = createRouter({ history: createWebHistory(), routes: constantRouterMap, scrollBehavior(to, from, savedPosition) { if (savedPosition) { return savedPosition } else { return { top: 0 } } }, }) //这里是我为了刷新的时候不调取获取路由信息的接口,做的本地缓存,因为刷新一次就要获取一遍用户信息和 //动态路由表信息太影响用户体验了,尤其是在网速差的情况下。没这方面需求的可以不用管 let asyncRouterMap = [] function handleLocalRouter() { if (sessionStorage.getItem('generateRoutes')) { asyncRouterMap = asyncRouterMap.concat( JSON.parse(sessionStorage.getItem('generateRoutes')) ) const generatedRoutes = generator(asyncRouterMap) generatedRoutes.push({ path: '/:pathMatch(.*)*', redirect: '/404', hidden: true, }) generatedRoutes.forEach((route) => { router.addRoute(route) }) } } //初始化路由 export function resetRouter() { let routers = router.getRoutes() routers.map((it) => { if (!['login', '403', ':pathMatch(.*)*'].includes(it.name)) { router.removeRoute(it.name) } }) } handleLocalRouter() export default router6.结束与优化好,至此,整个RBAC的前端权限方案设计到实现就已经宣告完成,其实还有很多需要优化的地方,比如把用户路由表信息缓存到本地临时缓存中,这样用户每次刷新页面的时候就不会因为vuex的特性需要再去请求一边接口。(但是老实说,我觉得这个优化方案还是不够好,因为将路由表存在本地缓存中就已经背离了安全性这一块,但是在网络较差的情况下,刷新就要调取角色信息接口,调取获取私有路由的接口,再到构建新的完整路由这个过程期间,页面会处于白屏状态,非常影响用户体验。因此,只能取此下策。到底要不要缓存,看个人的想法吧。) 还比如 await store.dispatch('user/GetInfo') await store.dispatch('async-router/GenerateRoutes') let accessRoutes = store.getters['async-router/addRouters'] accessRoutes.forEach((route) => { //用来判断是否是外链 if (!isHttp(route.path)) { router.addRoute(route) // 动态添加可访问路由表 } })这段获取用户信息->构建路由->添加动态路由的代码可以抽离出来,单独封装。还可以根据当前环境是否是 development来判断是否是开发环境,从而准备另外一套前端开发场景下使用的完整路由表,这样,就可以在不依赖后端的情况下,进行前端开发。另外还有侧边导航栏的处理,这个我没讲,一方面是相对简单,我们获取到格式化之后的动态路由数据的同时,其实也就是获取到了导航栏的菜单信息。 另一方面,每个人的项目页面布局方式不一样,导航栏的设计也会不一样。在此基础上,针对性的对数据进行修饰和改造即可。
-
rollup.js的个人理解 rollup也是一款静态资源打包工具。作用和webpack一样,但是比webpack轻量化。rollup和webpack的区别:webpack是一个静态资源打包器,从入口文件开始,webpack仅支持打包js,我们通过一个个loader打包其他不同类型的资源,通过插件实现额外的功能,最终将项目的所有文件编译成一个或多个文件输出出去。rollupjs也是静态资源打包成一个文件,rollup因为使用的前端模块化的方式是esm,于是有了tree shaking 特性。webpack由于要兼容commonjs,commonjs引入是全量引入,所以没有tree shakingwebpack 功能更加丰富,并且通过丰富的插件生态,如代码分割,适用于复杂场景和项目。rollup 更加轻便,它通过静态分析和Tree Shaking等技术,将代码模块按需打包,消除未使用的代码,以减小最终生成的包的体积。rollupjs 使用静态分析在编译时就确定依赖关系(所以在打包时会出现一下额外的依赖定义)webpack是运行时才进行依赖查找,所以在速度上会比较慢vite 是webpack的一个替代品。出现的原因是esm的出现和浏览器对esm的支持,使得在开发时运行不需要真正的编译,浏览器可以直接编译esm,所以在开发环境里,vite只是使用提供了开发服务器。生产环境下,vite 使用rollup进行代码编译。为了在生产环境中获得最佳的加载性能,最好还是将代码进行 tree-shaking、懒加载和 chunk 分割(以获得更好的缓存)。vite最大的特点是:冷启动热更新,生产环境用rollup,所以是tree shaking和静态分析。Tree ShakingTree Shaking技术其实就是代码按需打包技术,就是在打包过程中,只打包实际使用的代码,从而减少打包的体积。Tree Shaking的基础,我个人理解Tree Shaking的技术基础就是esm,正是esm的特性(具体如下),所以在打包过程中,可以做到区分代码是否用到。 Tree Shaking利用esm的特性:导入导出机制:ESM输出的是值的引用,这意味着如果模块内部的变量值发生变化,这些变化将反映到使用该变量的外部环境中。CommonJS输出的是值的拷贝,即使模块内部的值发生变化,外部环境中拷贝的值不会受到影响。依赖加载(解析)机制:ESM是编译时输出接口,而CommonJS是运行时加载。这意味着ESM在代码静态解析阶段就确定了模块的依赖关系,而CommonJS在运行时才解析模块依赖。ESM的import命令是异步的,而CommonJS的require()是同步的。这意味着ESM在加载模块时会分开模块的构建、实例化和执行,而CommonJS会同步加载整个模块Tree Shaking实现步骤(以Rollup的Tree Shaking实现方式举例)1. 识别依赖关系 :在打包过程中,工具(如Rollup)会分析每个模块中的导入和导出语句,构建出一个模块依赖图。这个图记录了每个模块之间的依赖关系。2. 标记被使用的代码 :通过静态分析技术,工具会遍历依赖图,并标记哪些变量、函数、类等被实际使用了。这些标记可以是通过变量引用、函数调用等方式进行识别。3. 剔除未使用的代码 :根据标记结果,工具会将未被使用的代码从最终生成的文件中剔除掉。这些未使用的代码可能是整个模块、模块中的某些函数或类等。4. 优化输出结果 :在剔除未使用代码后,工具会对输出结果进行进一步优化。它可能会进行变量重命名、函数内联等操作,以进一步减少文件大小和提高执行效率。Tree Shaking原理的核心在于静态分析和标记未使用代码。通过对模块依赖关系的分析,工具可以确定哪些代码是被实际使用的,哪些是未使用的。这种静态分析是在编译时进行的,因此可以在打包过程中进行优化,而不需要运行时的额外开销。需要注意的是,Tree Shaking只能消除那些在编译时可以确定未使用的代码。对于动态导入、条件导入等情况,工具可能无法准确判断哪些代码会被使用。因此,在使用Tree Shaking时,开发者需要注意编写可静态分析的代码,以确保最终生成的文件能够得到有效优化。由于是静态分析,所以我们在写代码的时候,需要注意自己的写法,简单来说,尽量的使用最小导入,例如,下面两个代码打包是不一样的:// 直接导入整个对象 import _ from 'lodash'; console.log(_.max([4, 2, 8, 6])) // 具名导入具体的函数 import { max } from 'lodash'; console.log(max([4, 2, 8, 6]))
-
前端工程化的思考 前端工程化定义前端工程化。是一种将软件工程的方法和思想应用于前端开发的实践,它旨在提高开发效率、降低开发成本、保证代码质量,这包括使用构建工具、实行模块化和组件化、自动化和持续集成等技术。前端工程化关注于开发流程的规范化、标准化,以及通过工具和框架解决前端开发和前后端协作中的问题。例如,使用脚手架工具、代码规范和格式化、热更新和Mock数据、自动化测试和持续部署等都是前端工程化的体现。模块化。指的是将复杂的程序或系统拆分成多个独立的模块,每个模块负责特定的功能,这些模块可以单独开发、测试和维护,模块化有助于提高代码的可维护性、复用性和管理性。在前端开发中,模块化通过将代码拆分为小的、独立的文件来实现,这些文件通过统一的拼装和加载来协同工作。JavaScript的模块化规范,如CommonJS,定义了模块的作用域和加载机制,有助于避免全局作用域的污染和提高代码的复用率。组件化。是模块化的一种表现形式,它专注于用户界面的拆分和维护。组件化将页面结构、样式和行为分离成独立的组件,每个组件都有自己的工程目录和所需资源,组件之间可以自由组合,形成完整的页面。这种方法的优点在于提高代码的复用性和维护性,同时也方便了多人协作和项目的扩展。总的来说,前端工程化、模块化和组件化共同促进了前端开发的效率和质量,它们是现代前端开发中不可或缺的部分。前端工程化是指将前端开发中的项目管理、构建、测试、部署等环节进行规范化和自动化,以提高开发效率、代码质量和团队协作能力的一种开发方式。具体来说,前端工程化涉及以下几个主要方面:项目架构:对项目的文件组织结构、模块划分、代码规范等进行规范化。良好的项目架构可以提高代码的可维护性和可扩展性。版本控制:使用版本控制系统(如Git)对代码进行管理,实现多人协作、版本回退、分支管理等功能,保证代码的版本和历史可追溯。自动化构建:使用构建工具(如Webpack、Gulp)将源码编译、压缩、合并、打包等操作自动化处理,以生成可部署或上线的最终代码。组件化与模块化:通过将页面拆分成一个个独立的组件和模块,可以更加灵活地组合和复用代码,提升开发效率和代码可维护性。组件化是在设计层面上,对于UI的拆分;而模块化是将一个大文件拆分成相互依赖的小文件,再进行统一的拼装和加载。自动化测试:自动化测试可以大大提升测试效率,减少人为错误。前后端分离与全栈工程化:前后端分离已经成为了现代Web开发的主流架构,前端和后端可以独立开发、独立部署、独立测试,大大提升了开发效率和产品质量。同时,全栈工程化的思想也在逐渐普及,即前后端使用统一的工程化标准和流程,进一步提升团队协作效率。前端工程化的目标是提升团队协作效率、提高代码质量、降低维护成本,并使前端开发更加规范和可持续。同时,它也能够适应快速迭代、多平台适配的现代前端开发需求。