搜索到
20
篇与
的结果
-
 rollup.js的个人理解 rollup也是一款静态资源打包工具。作用和webpack一样,但是比webpack轻量化。rollup和webpack的区别:webpack是一个静态资源打包器,从入口文件开始,webpack仅支持打包js,我们通过一个个loader打包其他不同类型的资源,通过插件实现额外的功能,最终将项目的所有文件编译成一个或多个文件输出出去。rollupjs也是静态资源打包成一个文件,rollup因为使用的前端模块化的方式是esm,于是有了tree shaking 特性。webpack由于要兼容commonjs,commonjs引入是全量引入,所以没有tree shakingwebpack 功能更加丰富,并且通过丰富的插件生态,如代码分割,适用于复杂场景和项目。rollup 更加轻便,它通过静态分析和Tree Shaking等技术,将代码模块按需打包,消除未使用的代码,以减小最终生成的包的体积。rollupjs 使用静态分析在编译时就确定依赖关系(所以在打包时会出现一下额外的依赖定义)webpack是运行时才进行依赖查找,所以在速度上会比较慢vite 是webpack的一个替代品。出现的原因是esm的出现和浏览器对esm的支持,使得在开发时运行不需要真正的编译,浏览器可以直接编译esm,所以在开发环境里,vite只是使用提供了开发服务器。生产环境下,vite 使用rollup进行代码编译。为了在生产环境中获得最佳的加载性能,最好还是将代码进行 tree-shaking、懒加载和 chunk 分割(以获得更好的缓存)。vite最大的特点是:冷启动热更新,生产环境用rollup,所以是tree shaking和静态分析。Tree ShakingTree Shaking技术其实就是代码按需打包技术,就是在打包过程中,只打包实际使用的代码,从而减少打包的体积。Tree Shaking的基础,我个人理解Tree Shaking的技术基础就是esm,正是esm的特性(具体如下),所以在打包过程中,可以做到区分代码是否用到。 Tree Shaking利用esm的特性:导入导出机制:ESM输出的是值的引用,这意味着如果模块内部的变量值发生变化,这些变化将反映到使用该变量的外部环境中。CommonJS输出的是值的拷贝,即使模块内部的值发生变化,外部环境中拷贝的值不会受到影响。依赖加载(解析)机制:ESM是编译时输出接口,而CommonJS是运行时加载。这意味着ESM在代码静态解析阶段就确定了模块的依赖关系,而CommonJS在运行时才解析模块依赖。ESM的import命令是异步的,而CommonJS的require()是同步的。这意味着ESM在加载模块时会分开模块的构建、实例化和执行,而CommonJS会同步加载整个模块Tree Shaking实现步骤(以Rollup的Tree Shaking实现方式举例)1. 识别依赖关系 :在打包过程中,工具(如Rollup)会分析每个模块中的导入和导出语句,构建出一个模块依赖图。这个图记录了每个模块之间的依赖关系。2. 标记被使用的代码 :通过静态分析技术,工具会遍历依赖图,并标记哪些变量、函数、类等被实际使用了。这些标记可以是通过变量引用、函数调用等方式进行识别。3. 剔除未使用的代码 :根据标记结果,工具会将未被使用的代码从最终生成的文件中剔除掉。这些未使用的代码可能是整个模块、模块中的某些函数或类等。4. 优化输出结果 :在剔除未使用代码后,工具会对输出结果进行进一步优化。它可能会进行变量重命名、函数内联等操作,以进一步减少文件大小和提高执行效率。Tree Shaking原理的核心在于静态分析和标记未使用代码。通过对模块依赖关系的分析,工具可以确定哪些代码是被实际使用的,哪些是未使用的。这种静态分析是在编译时进行的,因此可以在打包过程中进行优化,而不需要运行时的额外开销。需要注意的是,Tree Shaking只能消除那些在编译时可以确定未使用的代码。对于动态导入、条件导入等情况,工具可能无法准确判断哪些代码会被使用。因此,在使用Tree Shaking时,开发者需要注意编写可静态分析的代码,以确保最终生成的文件能够得到有效优化。由于是静态分析,所以我们在写代码的时候,需要注意自己的写法,简单来说,尽量的使用最小导入,例如,下面两个代码打包是不一样的:// 直接导入整个对象 import _ from 'lodash'; console.log(_.max([4, 2, 8, 6])) // 具名导入具体的函数 import { max } from 'lodash'; console.log(max([4, 2, 8, 6]))
rollup.js的个人理解 rollup也是一款静态资源打包工具。作用和webpack一样,但是比webpack轻量化。rollup和webpack的区别:webpack是一个静态资源打包器,从入口文件开始,webpack仅支持打包js,我们通过一个个loader打包其他不同类型的资源,通过插件实现额外的功能,最终将项目的所有文件编译成一个或多个文件输出出去。rollupjs也是静态资源打包成一个文件,rollup因为使用的前端模块化的方式是esm,于是有了tree shaking 特性。webpack由于要兼容commonjs,commonjs引入是全量引入,所以没有tree shakingwebpack 功能更加丰富,并且通过丰富的插件生态,如代码分割,适用于复杂场景和项目。rollup 更加轻便,它通过静态分析和Tree Shaking等技术,将代码模块按需打包,消除未使用的代码,以减小最终生成的包的体积。rollupjs 使用静态分析在编译时就确定依赖关系(所以在打包时会出现一下额外的依赖定义)webpack是运行时才进行依赖查找,所以在速度上会比较慢vite 是webpack的一个替代品。出现的原因是esm的出现和浏览器对esm的支持,使得在开发时运行不需要真正的编译,浏览器可以直接编译esm,所以在开发环境里,vite只是使用提供了开发服务器。生产环境下,vite 使用rollup进行代码编译。为了在生产环境中获得最佳的加载性能,最好还是将代码进行 tree-shaking、懒加载和 chunk 分割(以获得更好的缓存)。vite最大的特点是:冷启动热更新,生产环境用rollup,所以是tree shaking和静态分析。Tree ShakingTree Shaking技术其实就是代码按需打包技术,就是在打包过程中,只打包实际使用的代码,从而减少打包的体积。Tree Shaking的基础,我个人理解Tree Shaking的技术基础就是esm,正是esm的特性(具体如下),所以在打包过程中,可以做到区分代码是否用到。 Tree Shaking利用esm的特性:导入导出机制:ESM输出的是值的引用,这意味着如果模块内部的变量值发生变化,这些变化将反映到使用该变量的外部环境中。CommonJS输出的是值的拷贝,即使模块内部的值发生变化,外部环境中拷贝的值不会受到影响。依赖加载(解析)机制:ESM是编译时输出接口,而CommonJS是运行时加载。这意味着ESM在代码静态解析阶段就确定了模块的依赖关系,而CommonJS在运行时才解析模块依赖。ESM的import命令是异步的,而CommonJS的require()是同步的。这意味着ESM在加载模块时会分开模块的构建、实例化和执行,而CommonJS会同步加载整个模块Tree Shaking实现步骤(以Rollup的Tree Shaking实现方式举例)1. 识别依赖关系 :在打包过程中,工具(如Rollup)会分析每个模块中的导入和导出语句,构建出一个模块依赖图。这个图记录了每个模块之间的依赖关系。2. 标记被使用的代码 :通过静态分析技术,工具会遍历依赖图,并标记哪些变量、函数、类等被实际使用了。这些标记可以是通过变量引用、函数调用等方式进行识别。3. 剔除未使用的代码 :根据标记结果,工具会将未被使用的代码从最终生成的文件中剔除掉。这些未使用的代码可能是整个模块、模块中的某些函数或类等。4. 优化输出结果 :在剔除未使用代码后,工具会对输出结果进行进一步优化。它可能会进行变量重命名、函数内联等操作,以进一步减少文件大小和提高执行效率。Tree Shaking原理的核心在于静态分析和标记未使用代码。通过对模块依赖关系的分析,工具可以确定哪些代码是被实际使用的,哪些是未使用的。这种静态分析是在编译时进行的,因此可以在打包过程中进行优化,而不需要运行时的额外开销。需要注意的是,Tree Shaking只能消除那些在编译时可以确定未使用的代码。对于动态导入、条件导入等情况,工具可能无法准确判断哪些代码会被使用。因此,在使用Tree Shaking时,开发者需要注意编写可静态分析的代码,以确保最终生成的文件能够得到有效优化。由于是静态分析,所以我们在写代码的时候,需要注意自己的写法,简单来说,尽量的使用最小导入,例如,下面两个代码打包是不一样的:// 直接导入整个对象 import _ from 'lodash'; console.log(_.max([4, 2, 8, 6])) // 具名导入具体的函数 import { max } from 'lodash'; console.log(max([4, 2, 8, 6])) -
前端工程化的思考 前端工程化定义前端工程化。是一种将软件工程的方法和思想应用于前端开发的实践,它旨在提高开发效率、降低开发成本、保证代码质量,这包括使用构建工具、实行模块化和组件化、自动化和持续集成等技术。前端工程化关注于开发流程的规范化、标准化,以及通过工具和框架解决前端开发和前后端协作中的问题。例如,使用脚手架工具、代码规范和格式化、热更新和Mock数据、自动化测试和持续部署等都是前端工程化的体现。模块化。指的是将复杂的程序或系统拆分成多个独立的模块,每个模块负责特定的功能,这些模块可以单独开发、测试和维护,模块化有助于提高代码的可维护性、复用性和管理性。在前端开发中,模块化通过将代码拆分为小的、独立的文件来实现,这些文件通过统一的拼装和加载来协同工作。JavaScript的模块化规范,如CommonJS,定义了模块的作用域和加载机制,有助于避免全局作用域的污染和提高代码的复用率。组件化。是模块化的一种表现形式,它专注于用户界面的拆分和维护。组件化将页面结构、样式和行为分离成独立的组件,每个组件都有自己的工程目录和所需资源,组件之间可以自由组合,形成完整的页面。这种方法的优点在于提高代码的复用性和维护性,同时也方便了多人协作和项目的扩展。总的来说,前端工程化、模块化和组件化共同促进了前端开发的效率和质量,它们是现代前端开发中不可或缺的部分。前端工程化是指将前端开发中的项目管理、构建、测试、部署等环节进行规范化和自动化,以提高开发效率、代码质量和团队协作能力的一种开发方式。具体来说,前端工程化涉及以下几个主要方面:项目架构:对项目的文件组织结构、模块划分、代码规范等进行规范化。良好的项目架构可以提高代码的可维护性和可扩展性。版本控制:使用版本控制系统(如Git)对代码进行管理,实现多人协作、版本回退、分支管理等功能,保证代码的版本和历史可追溯。自动化构建:使用构建工具(如Webpack、Gulp)将源码编译、压缩、合并、打包等操作自动化处理,以生成可部署或上线的最终代码。组件化与模块化:通过将页面拆分成一个个独立的组件和模块,可以更加灵活地组合和复用代码,提升开发效率和代码可维护性。组件化是在设计层面上,对于UI的拆分;而模块化是将一个大文件拆分成相互依赖的小文件,再进行统一的拼装和加载。自动化测试:自动化测试可以大大提升测试效率,减少人为错误。前后端分离与全栈工程化:前后端分离已经成为了现代Web开发的主流架构,前端和后端可以独立开发、独立部署、独立测试,大大提升了开发效率和产品质量。同时,全栈工程化的思想也在逐渐普及,即前后端使用统一的工程化标准和流程,进一步提升团队协作效率。前端工程化的目标是提升团队协作效率、提高代码质量、降低维护成本,并使前端开发更加规范和可持续。同时,它也能够适应快速迭代、多平台适配的现代前端开发需求。
-
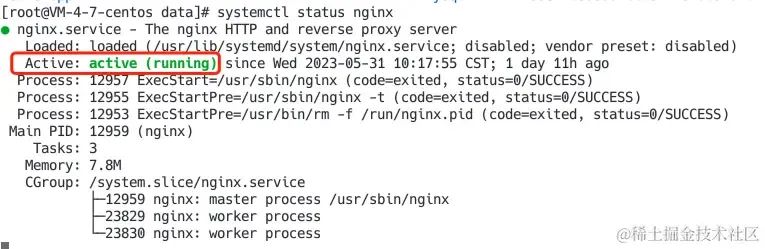
【整理】Nginx基础知识 Nginx相关知识Nginx是在前端服务部署时是很重要的一部分,也是部署的基础,学会了通过Nginx部署前端资源,才能继续后续的一系列进阶。一、了解一点简单的Nginx知识本节内容作为基础知识,如果熟悉Nginx可以略过,如果不熟悉可以实际操作一下。现在服务器安装Nginx很简单,一般只需要两行命令即可,安装完成后,启动服务。 # 安装nginx yum install -y nginx # 启动nginx systemctl start nginx # 查看nginx运行状态 systemctl status nginx当我们看到下图,说明你的Nginx运行正常,此时Nginx会启动服务,默认80端口。此时如果我们的服务器外网防火墙 80端口开启,那么访问外网IP,就能看到Nginx启动的服务Nginx的配置文件,一般位于 /etc/nginx目录下,具体内容如下:我们基本只需要关注文件 nginx.conf和 conf.d目录,下面是一份 nginx.conf配置文件,不懂也不要怕,基本都不需要改动,默认80服务已经开启了。 user nginx; # nginx进行运行的用户 error_log /var/log/nginx/error.log; # 错误日志 http { log_format main ...; # nginx日志格式 access_log /var/log/nginx/access.log main; # 日志位置 # 引入的nginx配置文件,可以将server放在该目录下,方便管理 include /etc/nginx/conf.d/*.conf; # 一个nginx服务一个server server { listen 80; # 服务启动的端口 server_name _; # 服务域名或IP root /usr/share/nginx/html; # 服务指向的文件地址 error_page 404 /404.html; # 找不到资源重定向到404页面 location = /40x.html {}; error_page 500 502 503 504 /50x.html; # 系统错误重定向50x页面 location = /50x.html {}; } # server { # listen 443; # 支持https协议 # server_name _; # root /usr/share/nginx/html; # ... # } }我们可以看到该文件分成了多层第一层:user、error_log、http第二层:log_format、access_log、include、server在http下可以有多个 Server,启动多个服务,但如果都写在一个文件里面,文件就越来越大了,那么为了便于管理多个服务,我们要对 nginx.conf进行拆分。conf.d目录下一般是空的,我们新建文件 web.conf或者任意命名的以.conf结尾的文件即可被Nginx使用,内容为: server { listen 80; server_name _; root /usr/share/nginx/html; error_page 404 /404.html; location = /40x.html {}; error_page 500 502 503 504 /50x.html; location = /50x.html {}; }由于这里使用了80端口,之前nginx.conf文件server中listen为80的可以删除了。此时nginx.conf中的文件内容为: user nginx; # nginx进行运行的用户 error_log /var/log/nginx/error.log; # 错误日志 http { log_format main ...; # nginx日志格式 access_log /var/log/nginx/access.log main; # 日志位置 # 引入的nginx配置文件,可以将server放在该目录下,方便管理 include /etc/nginx/conf.d/*.conf; }include /etc/nginx/conf.d/*.conf; 我们看到这一行语句发现,include帮助我们引用conf.d下以.conf结尾的配置文件。完成后执行nginx指令 # 检查nginx配置文件是否正确,如果错误会提示具体的错误信息 nginx -t # 重新启动nginx服务 nginx -s reload观察日志,此时发现Nginx就重新启动了,读取的是新的配置文件。其他操作nginx的指令 nginx -s stop nginx -s start二、启动一个简单的Nginx服务一台服务器或PC,安装并启动Nginx服务/data/web两个html文件 index.html, about.html1、index.html或 about.html <!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>nginx</title> </head> <body> 通过nginx部署的第一个服务 </body> </html>2、修改 /etc/nginx/conf.d/web.conf server { listen 80; server_name localhost; root /data/web; index index.html; }执行 nginx -t确认配置文件修改没问题,再执行 nginx -s reload重启Nginx,此时我们访问外网IP(默认80端口,下面默认都是访问80端口),可以看到这样我们的静态资源文件就部署好了,通过url访问资源:http://xxxx/index.htmlhttp://xxxx/about.html三、部署单页面应用我们快速创建一个CRA单页面应用,修改App.js文件,这里使用 react-router-dom@61、Hash模式 import { HashRouter, Routes, Route, Link } from "react-router-dom"; import './App.css'; function App() { return ( <div className="App"> <HashRouter basename="/"> <div style={{marginBottom: 20}}> <Link style={{marginRight: 20}} to="/">Home</Link> <Link to="/about">About</Link> </div> <Routes> <Route path="/" element={<div>home</div>}></Route> <Route path="/about" element={<div>about</div>} /> </Routes> </HashRouter> </div> ); } export default App;我们执行 yarn build,然后将 build目录下的文件迁移到 /data/web下,再访问服务器IP,发现访问正常,路由切换也没有问题,即部署成功。2、History模式 import { BrowserRouter, ... } from "react-router-dom";将Hash模式中的代码修改为BrowserRouter,运行本地项目,路由切换正常,该路由是History模式同样执行 yarn build生成 build目录,将该目录下的文件迁移到上一步服务器的目录/data/web下,然后访问外网IP,发现渲染效果和上图一样,但是当我们点击About页面,然后刷新浏览器发现,出现了404。先说解决办法,然后解释下原因,修改Nginx配置 web.conf增加一行try_files配置,当请求的地址找不到时,重新指向index.html文件 server { listen 80; server_name localhost; root /data/www/; location / { try_files $uri $uri/ /index.html; index index.html; } }重启nginx nginx -t、nginx -s reload 再次刷新页面,发现页面访问正常了,切换也没有问题。3、为什么hash模式不会出现404,而history模式会出现404?了解下这两种模式的区别就知道答案了1)Hash模式在hash路由模式下,URL中的Hash值(#后面的部分)用来表示应用的状态或路由信息。当用户切换路由时,只有Hash部分发生变化,并没有向服务器发出请求,就做到了浏览器对于页面路由的管理。Hash模式下,URL和路由路径由#号分隔:http://example.com/#/about?query=abc当 #后面的路径发生变化时,会触发浏览器的hashchange事件,通过hashchange事件监听到路由路径的变化,从而导航到不同的路由页面。Hash模式 #后面的路径并不会作为URL出现在网络请求中。例如对于输入的example.com/#/about^[1]^ ,实际上请求的URL是example.com/^[2]^ ,所以不管输入的Hash路由路径是什么,实际网络请求的都是主域名或 IP:Port2)History模式History路由模式下,调用浏览器HTML5中 historyAPI来管理导航。URL和路径是连接在一起的,路由的路径包含在请求的URL里面,路由路径作为URL的一部分一起发送。History模式下,URL路由格式为:http://example.com/about&query=abc当我们向服务器发出请求时,服务器会请求对应的路径的资源综上,当我们打开入口文件index.html的路径时,切换url此时是本地路由,访问正常,但是当我们处于非入口页面时,刷新浏览器,此时发出请求,由于服务器就找不到资源路径了,变成了404。而对于Hash模式来说,总是请求的根路径,所以不会出现这种情况。四、配置反向代理、负载均衡1、反向代理反向代理的用途很多,这里我们看一个常用的,代理请求的接口。我们在发布时前端的域名和后端api服务的域名经常不一致,此时就可以使用Nginx配置反向代理来解决这个问题。 server { location /api { proxy_pass http://backend1.example.com; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; } }代理的时候要注意添加必要的参数,帮助后端获取一些客户端的请求数据proxy_set_header Host $host; :客户端请求的主机名(Host),不加的话,后端无法获取主机名信息proxy_set_header X-Real-IP $remote_addr;:用户的真实IP(X-Real-IP),如果不设置,后端只能拿到代理服务器的IPproxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;代理链路,如果用户中间经过了多个代理服务器,如果不加这个参数,那么后端服务将无法获取用户的真实来源2、负载均衡Nginx可以作为负载均衡服务器使用,通过配置upstream来分发流量,同时可以配置一些参数:weight:分发权重ip_hash:配置始终将ip的请求始终转发到同一台后端服务器。max_fails: 将某个后台服务标记为不可用之前,允许请求失败的次数backup:标记当前服务为备用服务down:暂时不可用 upstream api { ip_hash; server backend1.example.com; server backend2.example.com; # server backend1.example.com weight=5; } server { location /api { proxy_pass http://api; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; } }五、配置nginx日志Nginx日志也是很重要的一个内容,在我们请求资源出现问题时,要排查请求的资源是否到达Nginx,而且请求日志可以记录很多有用的信息。 log_format gzip '$remote_addr - $remote_user [$time_local] ' : '"$request" $status $bytes_sent ' : '"$http_referer" "$http_user_agent" "$gzip_ratio"'; access_log /var/logs/nginx-access.log gzip buffer=32k;nginx日志主要涉及 access_log,log_formatlog_format: 日志格式,通过nginx内置的变量来读取和排列,通常默认即可access_log: 日志输出的地址、是否压缩、buffer是否当日志大于32k后吸入磁盘六、其他常用配置1、配置Gzip压缩作为前端性能优化的一种方式,Gzip是简单且有效的,尽管目前前端对于静态资源会进行压缩,但Gzip依然可以在网络传输过程中对文件进行压缩下面这些字段可以放在 http、server、location指令模块 http { # 开启关闭 gzip on; # 压缩的文件类型 gzip_types text/plain text/css application/javascript; # 过小的文件没必要压缩 gzip_min_length 1000; # 单位Byte gzip_comp_level 5; # 压缩比,默认1,范围时1-9,值越大压缩比最大,但处理最慢,所以设置5左右比较合理。 }2、配置请求头允许客户端请求在http请求中添加以下划线格式命名的参数该字段可以放在 http指令模块 http { underscores_in_headers on; } ``` **允许客户端上传文件最大不超过1M,在开发上传接口时一定要注意,否则导致上传失败** 该字段可以放在`http、server、location`指令模块 http { client_max_body_size 1m; } ### 3、浏览器缓存配置 **缓存也是前端优化的一个重点,合理的缓存可以提高用户访问速度** 该字段可以放在`http、server、location`指令模块 配置浏览器缓存的有三个地方 #### 1)后端服务,配置请求头 后端根据语言不同,配置关键字段即可 #### 2)代理服务器(Nginx)配置缓存请求头 location /static { # /static匹配到的资源有效期设置为1d; expires 1d; # /设置资源有效期为一周; # expires max-age=604800; # 设置浏览器可以被缓存,设置7天后资源过期 add_header Cache-Control "public, max-age=604800"; # 阻止浏览器缓存动态内容 # add_header Cache-Control "no-cache, no-store, must-revalidate"; # 禁用浏览器缓存 # add_header Cache-Control "no-store, private, max-age=0";} 我们发现响应头的过期时间更新了 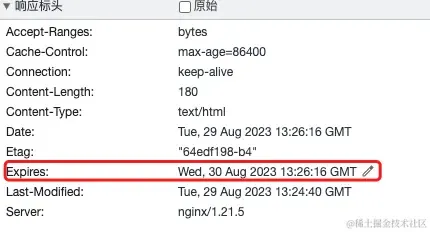 #### 3)在前端资源中通过meta声明缓存信息 <meta http-equiv="Cache-Control" content="no-cache, no-store, must-revalidate"><meta http-equiv="Expires" content="0"> ### 4、跨域处理 > 通过反向代理,已经处理了请求域名和端口不一致的跨域问题,但有局限性。Nginx有专门方法配置请求资源的跨域 该字段可以放在 `server、location`指令模块,通过配置头部字段,做跨域处理 server {location / { # 允许所有来源的跨域请求 add_header Access-Control-Allow-Origin *; # 允许特定的HTTP方法(GET、POST等) add_header Access-Control-Allow-Methods "GET, POST, OPTIONS, PUT, DELETE"; # 允许特定的HTTP请求头字段 add_header Access-Control-Allow-Headers "Origin, X-Requested-With, Content-Type, Accept"; # 响应预检请求的最大时间 add_header Access-Control-Max-Age 3600; # 允许携带身份凭证(如Cookie) add_header Access-Control-Allow-Credentials true; # 处理 OPTIONS 预检请求 if ($request_method = 'OPTIONS') { add_header Access-Control-Allow-Methods "GET, POST, OPTIONS, PUT, DELETE"; add_header Access-Control-Allow-Headers "Origin, X-Requested-With, Content-Type, Accept"; add_header Access-Control-Max-Age 3600; add_header Access-Control-Allow-Credentials true; add_header Content-Length 0; add_header Content-Type text/plain; return 204; } }}
-
云服务器Docker内部署服务后,端口无法访问? 云服务器Docker内部署服务后,端口无法访问,可以按照以下思路进行排查: 以【docker run --name my-nginx -d -p 9395:80 nginx】举例:查看Docker映射是否正确,可使用docker ps命令查看。Docker是否设置端口映射,你的nginx是否放开80端口外部访问判断云服务器安全组是否放通相应端口。例如:查看你的云服务器防火墙是否放开9395端口外部访问。在/etc/sysctl.conf文件内,找到net.ipv4.ip_forward,将默认的参数0改为1,然后执行sysctl -p命令即可。总结:当你检测你的操作都没问题,还不行的话, 只能是服务器的问题,既然是服务器的问题,那就得找客服。
-
本地navcat怎么连接云服务器里的数据库 本地navcat怎么连接云服务器里的数据库首先要检查云服务器里的应用管理-是否有对应的数据库。然后通过运行 cat ~lighthouse/credentials.txt 来查看数据库的登录密码(云服务器数据库的默认密码强度足够高,如果你想自己设置,一定要设置足够复杂的密码,这是血淋淋的教训)。然后把你的ip 端口 用户名 密码输入navcat。下面是可能遇到的问题:1130 - Host '222.92.143.173'is not allowed to connect to this MariaDB server错误消息“1130 - Host '222.92.143.173' is not allowed to connect to this MariaDB server”表明来自特定IP地址(在本例中是222.92.143.173)的客户端尝试连接到MariaDB服务器时,该服务器的配置不允许来自该IP的连接。这通常是因为MariaDB的 user表中的 host字段没有为相应的用户配置为允许该IP地址或任何IP地址(通常使用通配符 %表示)。要解决这个问题,您可以采取以下步骤:连接数据库ssh远程到对于的linux服务器,使用mysql -u root -p 回车输入密码再次回车进行登录登录MariaDB后,显示MariaDB [(none)]> 如果你希望选择一个数据库作为当前工作数据库,可以使用 USE 语句。例如,如果你想选择名为 mydatabase 的数据库,可以执行以下命令:USE mydatabase;访问MariaDB服务器:您需要有足够的权限来登录到MariaDB服务器。这通常意味着您需要服务器的SSH访问权限以及MariaDB的root用户或其他具有足够权限的用户的凭据。检查用户权限:登录到MariaDB后,您可以检查 mysql.user表来查看特定用户的权限设置。使用以下SQL命令:SELECT user, host FROM mysql.user WHERE user = 'your_username';将 your_username替换为尝试连接的用户名。这将显示该用户的所有主机条目。更新用户权限:如果 host字段中没有条目允许来自222.92.143.173的连接,您可能需要更新它。如果您想允许该用户从任何IP地址连接,可以使用以下命令(注意,这可能会带来安全风险,因为它允许从任何网络地址进行连接):GRANT ALL PRIVILEGES ON *.* TO 'your_username'@'%' IDENTIFIED BY 'your_password' WITH GRANT OPTION; FLUSH PRIVILEGES;或者,如果您只想允许来自特定IP的连接,可以这样做:GRANT ALL PRIVILEGES ON *.* TO 'your_username'@'222.92.143.173' IDENTIFIED BY 'your_password' WITH GRANT OPTION; FLUSH PRIVILEGES;但是,请注意,如果用户已经存在并且您只是想要更改其主机设置,您可能需要先删除现有的用户条目(这可能会导致数据丢失,除非您非常确定自己在做什么),然后重新创建它,或者使用 UPDATE语句直接修改 mysql.user表(这通常不推荐,因为它可能会绕过MariaDB的安全机制)。考虑安全性:允许从任何IP地址连接可能会使您的数据库面临安全风险。相反,考虑配置防火墙规则以限制对MariaDB端口的访问,并仅允许受信任的IP地址进行连接。重启MariaDB服务:在某些情况下,您可能需要重启MariaDB服务才能使更改生效。这可以通过您的服务器的服务管理工具来完成。测试连接:最后,从222.92.143.173或其他允许的IP地址尝试重新连接,以确保更改已正确应用。注意云服务器的防火墙防火墙只控制服务器的入流量,出流量默认允许所有请求,可以设置允许或禁止公网或内网对轻量应用服务器实例的访问,未配置规则等同于禁止访问。如何配置防火墙规则如有发现无法访问接口和静态资源的情况,注意检查防火墙。